
Ad aprile, il New York Times aveva contattato OpenAI e Microsoft per studiare un accordo che risolvesse i problemi legati all’uso dei suoi articoli per addestrare i chat bot automatizzati. La società nel settore dei media aveva messo in guardia le due aziende, dopo il rilascio molto pubblicizzato di ChatGPT e BingChat, sul fatto che la loro tecnologia violava opere protette da copyright. I termini per la risoluzione della disputa prevedevano un accordo di licenza e l’istituzione di paletti intorno agli strumenti di intelligenza artificiale generativa, anche se le trattative non sono riuscite a raggiungere una tregua.
Con l’impasse dei negoziati, mercoledì 27 dicembre il New York Times è diventato la prima grande società di media a intentare una causa per i nuovi problemi di copyright sollevati dalla tecnologia, una causa che potrebbe avere implicazioni di vasta portata sul settore dell’editoria giornalistica. Potenzialmente in gioco: la sostenibilità finanziaria dei media in un panorama in cui i lettori possono ignorare le fonti dirette a favore di risultati di ricerca generati da strumenti di intelligenza artificiale. La causa potrebbe spingere OpenAI ad accettare un costoso accordo di licenza, poiché potrebbe crearsi una giurisprudenza sfavorevole che le impedirebbe di utilizzare materiale protetto da copyright per addestrare il suo chat bot.


La denuncia del New York Times
La denuncia del New York Times si basa sulle argomentazioni portate in altre cause per violazione del copyright contro società di IA, evitando però alcune delle loro insidie. In particolare, non avanza la tesi che il chat bot di OpenAI sia di per sé un’opera che viola il copyright e punta su estratti letterali di articoli generati dalla tecnologia dell’azienda, prove che diversi tribunali che supervisionano casi simili hanno richiesto.
La causa presenta ampie prove di prodotti di OpenAI e Microsoft che mostrano stralci di articoli ripresi quasi parola per parola quando viene inserito un prompt adeguato, consentendo agli utenti di aggirare il paywall. Queste risposte, sostiene il New York Times, vanno ben oltre i frammenti di testo tipicamente mostrati nei normali risultati di ricerca. Un esempio: Bing Chat ha copiato tutte le prime 396 parole, tranne due, dell’articolo del 2023 I segreti che Hamas conosceva sull’esercito di Israele. Un reperto mostra un centinaio di altre situazioni in cui il GPT di OpenAI è stato addestrato con articoli del New York Times e li ha memorizzati, con le parole copiate in rosso e le differenze in nero.

Un reperto della denuncia del New York Times che mostra il plagio di un prodotto OpenAI
Secondo due tribunali che si occupano di casi identici, i querelanti dovranno probabilmente dimostrare che le opere prodotte dai chat bot che presumibilmente violano il copyright sono identiche al materiale protetto da copyright su cui sono stati presumibilmente addestrati. Ciò rappresenta potenzialmente un problema importante per gli artisti che hanno fatto causa a StabilityAI, poiché quest’ultima ha ammesso che “probabilmente nessuna delle immagini di output di Stable Diffusion fornite in risposta a un particolare Text Prompt corrisponde a un’immagine specifica nei dati di addestramento”.
Il giudice distrettuale degli Stati Uniti William Orrick ha scritto in una sentenza che respingeva le richieste di risarcimento contro i generatori di IA ad ottobre che “non è convinto” che le richieste di risarcimento del copyright “possano sopravvivere in assenza di accuse di ‘somiglianza sostanziale'”. Un mese dopo, il giudice distrettuale degli Stati Uniti Vince Chhabria ha messo in dubbio che Meta possa essere ritenuta responsabile di violazione in una causa intentata da autori in assenza di prove che dimostrino che uno qualsiasi degli output “possa essere inteso come rifusione, trasformazione o adattamento dei libri dei querelanti”.
“È necessario mostrare un esempio di output sostanzialmente simile al proprio lavoro per avere un caso che possa sopravvivere all’archiviazione”, afferma Jason Bloom, presidente dello studio specializzato in proprietà intellettuale Haynes Boone. “È stato molto difficile dimostrarlo in altri casi”.
Una strada in salita?
I risultati hanno la duplice funzione di fornire una prova inconfutabile che gli articoli del New York Times sono stati utilizzati per addestrare i sistemi di intelligenza artificiale. Poiché i set di dati di addestramento sono in gran parte scatole nere, nella maggior parte delle altre cause i querelanti non sono stati in grado di affermare con certezza che le loro opere sono state incluse. Gli autori che hanno fatto causa a OpenAI, per esempio, possono solo indicare che ChatGPT ha generato riassunti e analisi approfondite dei temi dei loro romanzi come prova che l’azienda ha usato i loro libri.
L’approccio del Times nella sua causa è in contrasto con la denuncia della Authors Guild, che ha scelto di limitare il suo caso alle questioni relative all’ingestione di materiale protetto da copyright per addestrare i sistemi di intelligenza artificiale. “La legge sul copyright ha sempre insistito sulla somiglianza sostanziale”, afferma Mary Rasenberger, direttrice esecutiva dell’organizzazione. “E quando si ha una riproduzione esatta, questa è per definizione sostanzialmente simile”.
Il New York Times sottolinea di essere la più grande fonte di dati proprietari che è stata utilizzata per addestrare il GPT (e la terza in assoluto dopo Wikipedia e un database di documenti brevettuali statunitensi). In mezzo a un oceano di contenuti spazzatura che si trovano comunemente online, gli articoli di editori affidabili stanno assumendo una nuova importanza come dati di addestramento, perché hanno maggiori probabilità di essere ben scritti e accurati rispetto ad altri contenuti che si trovano tipicamente online. In questo contesto, la causa potrebbe essere la prima di molte altre, dato che gli archivi di notizie diventano sempre più preziosi per le aziende tecnologiche. Axel Springer, proprietario di Politico e Business Insider, questo mese ha raggiunto un accordo con OpenAI sui suoi contenuti per addestrare i prodotti GPT, scegliendo di accettare denaro dal gigante dell’intelligenza artificiale invece di avviare una propria battaglia legale.
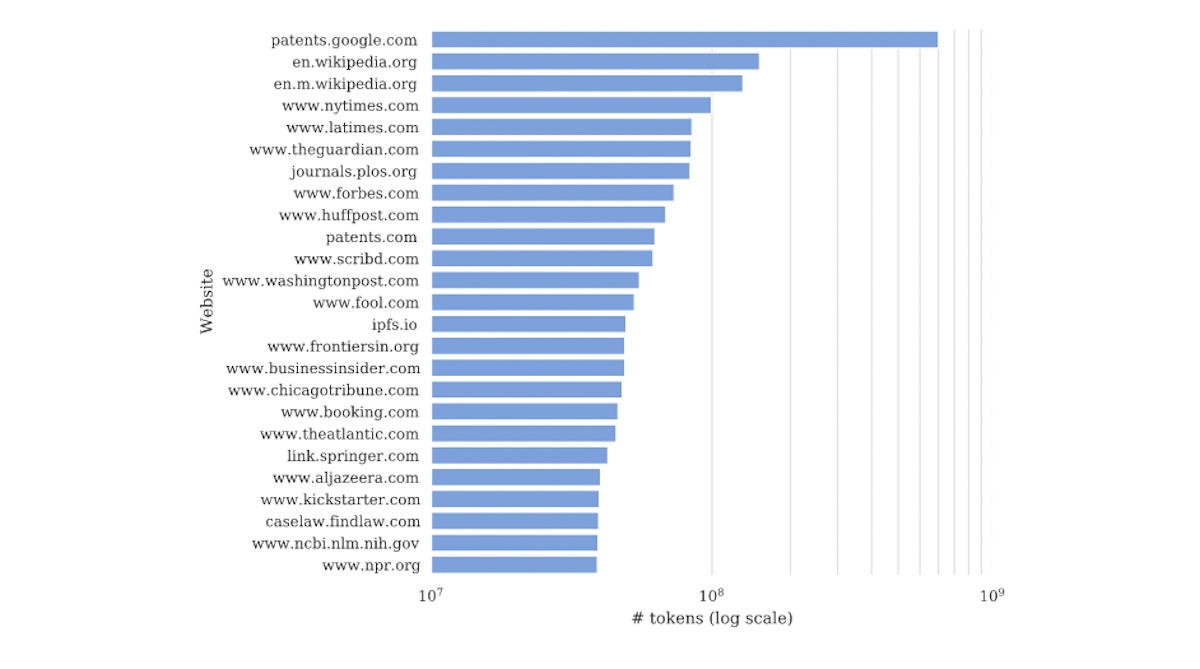
Nella sua denuncia, il New York Times afferma che si tratta della più grande fonte di dati proprietari utilizzati per addestrare GPT (e la terza in assoluto dietro solo Wikipedia e un database di documenti sui brevetti statunitensi)
Tuttavia, il New York Times potrebbe trovarsi di fronte a una strada tutta in salita rispetto ad altre cause intentate da autori di contenuti narrativi. La causa intentata dalla Authors Guild cerca probabilmente di rappresentare esclusivamente una classe di scrittori di narrativa, dal momento che i fatti non sono soggetti a diritto d’autore, il che rende più difficile la denuncia di violazione di articoli di cronaca o di libri che non siano di narrativa. Per il New York Times sarà fondamentale dimostrare che i prodotti di OpenAI non si limitano a fornire i fatti, ma copiano la composizione in cui sono presentati.
La denuncia prevede richieste di risarcimento per violazione del diritto d’autore, violazione contributiva del diritto d’autore, diluizione del marchio, concorrenza sleale e violazione del Digital Millennium Copyright Act. Un aspetto della causa che la distingue da altre contro aziende di IA è l’accusa di aver falsamente attribuito “allucinazioni” al New York Times.
“In risposta a un prompt che richiedeva un saggio informativo sulle notizie riportate dai principali quotidiani secondo cui il succo d’arancia è collegato al linfoma non-Hodgkin, un modello GPT ha completamente inventato che ‘il New York Times ha pubblicato un articolo il 10 gennaio 2020, intitolato ‘Uno studio scopre un possibile collegamento tra il succo d’arancia e il linfoma non-Hodgkin’”, si legge nella denuncia. “Il New York Times non ha mai pubblicato tale articolo”.
L’accertamento della violazione potrebbe comportare risarcimenti ingenti, poiché il massimo previsto dalla legge per ogni violazione intenzionale è di 150.000 dollari.
Traduzione di Nadia Cazzaniga
Da non perdere su The Hollywood Reporter
-

-
Tecnologia
Command Z: Steven Soderbergh presenta la sua nuova serie sci-fi ad una proiezione segreta di New York

-
Industry
Pupi Avati alla festa Sky: “C’è una nuova generazione di autori straordinari, il cinema italiano si sta riprendendo”

-
Mercati
È finita la bolla Covid, Rai Cinema annuncia: nel 2024 produrrà meno film. Paolo Del Brocco: “Si torna al pre-pandemia”

-
Tecnologia
David McCallum, la star di Organizzazione U.N.C.L.E. e di NCIS è morta all’età di 90 anni

-
Mercati
Disney investe 1,5 miliardi di dollari in Epic Games. “Creeremo un nuovo universo virtuale con Fortnite”
